ゲーミングキーボードの選び方|メカニカルスイッチ・配列・接続方式を解説
he2dy
He2dyTechLAB


海外記事を翻訳したものなので、表現や解釈に一部違いがある可能性があります。
出典:Ars Technica
参考:Mozilla Blog / Mozilla Hacks
先月、MozillaのCTOがAIを活用した脆弱性検出について、「ゼロデイの時代を終わらせる可能性がある」「防御側がついに決定的に勝利する機会を得た」と述べた際、業界の反応はかなり懐疑的でした。
これまでAI分野では、印象的な成果だけが強調され、より複雑な現実や細かい検証内容が省略されたまま、大きく宣伝されるケースが少なくなかったためです。
こうした懐疑的な見方を意識したのか、Mozillaは木曜日、AnthropicのClaude Mythos Previewを活用し、2か月間でFirefoxのセキュリティ脆弱性271件を発見した過程を詳しく公開しました。
Mozillaのエンジニアによると、今回の成果が実用段階に近づいた理由は大きく2つあります。
1つ目はAIモデル自体の性能向上。
2つ目は、Firefoxのソースコードを分析する際にClaude Mythos Previewを支援するため、Mozillaが独自に構築したカスタムの**ハーネス(harness)**システムです。
Mozillaのエンジニアは、過去のAIを使った脆弱性検出について、「使いものにならない出力」が多かったと説明しています。
一般的に、開発者が特定のコードブロックをAIモデルに分析させると、モデルは一見もっともらしいバグレポートを大量に生成します。
しかし、実際に開発者が検証してみると、その多くは細部に誤りや幻覚が含まれており、結局は人間が従来通りに脆弱性を確認し直す必要がありました。
Mozilla Distinguished EngineerのBrian Grinstead氏は、今回のClaude Mythos Previewの使い方は以前とは大きく違っていたと説明しています。
最大の違いは、**エージェント・ハーネス(agent harness)**の利用です。
これは、LLMを特定の作業フローに沿って段階的に動かすためのコードレイヤーです。
このようなハーネスを効果的に使うには、プロジェクトごとの意味構造、開発ツール、テスト環境、プロセスに合わせたかなり高度なカスタマイズが必要になります。
Grinstead氏は、このハーネスを「目標を達成するためにLLMを動かすコード」と説明しています。
このシステムはモデルに対して、「このファイルからバグを見つけてください」といった指示を与えます。
同時に、ファイルの読み書き、テストの実行、結果の確認といったツールを提供し、作業が完了するまで繰り返し実行します。
Mozillaのハーネスは、Claude Mythos Previewに対して、実際のMozilla開発者が使っているものと同じツールやパイプラインへのアクセスを与えました。
そこには、Firefoxのテスト用に用意された特別なビルドも含まれています。
Grinstead氏は、ハーネス環境について次のように説明しています。
明確で決定的な成功シグナル、または検証基準を定義できれば、モデルに対して作業を継続させることができます。
たとえば、メモリ安全性の問題を探す場合、MozillaはFirefoxのsanitizerビルドを使用します。
もしクラッシュを発生させることができれば、それは成功とみなせます。
Mozillaはエージェントに特定のソースファイルを与え、「このファイルには問題があることがわかっているので、それを見つけてください」と指示します。
するとモデルはテストケースを作成し、既存のファジングシステムやツールを使ってそれを実行します。
モデルは「このHTMLをこのように構成すれば問題が起きるかもしれない」と判断し、その内容をツールに渡します。
ツールは成功したかどうかを返し、成功した場合は追加の検証ステップに進みます。
この追加検証では、2つ目のLLMが1つ目のLLMの出力を評価します。
Mozillaによると、高いスコアを得た結果は、従来の脆弱性検出手法と同じレベルの信頼性を持つとされています。
Grinstead氏は、最終的に生成されるバグレポートについて、「誤検出はほぼない」と述べています。

今回の公開では、Claude Mythos Previewと一部のClaude Opus 4.6などが発見した271件の脆弱性のうち、12件のBugzillaレポートも公開されました。
これらのレポートには、メモリ安全性の問題を引き起こすHTMLやその他のコード形式のテストケースが含まれています。
また、Firefoxのセキュリティ脆弱性として認定されるためのMozilla内部基準を満たしていると説明されています。
あるセキュリティ研究者は、これらのレポートを大まかに確認したうえで、「かなり印象的だ」と評価したとされています。
Grinstead氏は、過去のAIによる脆弱性報告とは異なり、今回はハーネスを使った分析と2つ目のLLMによる検証を経ているため、従来よりも高い信頼性を確保できたと強調しています。
同氏は、この点こそが現在の規模で運用できるようになった核心だと説明しています。
エンジニアは「これは実際の問題だ」と判断したうえで修正作業を進めることができ、修正後には問題が解決されたかどうかを明確に確認できます。
さらに、そのテストケースをコードベースに組み込むことで、同じ問題の再発を防ぐこともできます。
一方で、Mozillaが示した「AIによる脆弱性検出はゲームチェンジャーになる」という主張に対しては、依然として強い懐疑論もあります。
批判的な見方の一つは、271件の脆弱性すべてに個別のCVE番号が付与されていないという点です。
これに対してMozillaは、多くの開発組織と同じように、内部で発見した脆弱性については個別のCVEを付与せず、まとめて処理する場合があると説明しています。
また、こうしたBugzillaレポートは、パッチ適用後も数か月間は非公開にされることが一般的です。
今回Mozillaは一部のレポートを公開しましたが、それでも批判側は「選ばれた事例にすぎない」と主張する可能性があります。
Mozillaによると、271件の脆弱性のうち180件は、Mozilla内部基準で高い重要度を示すsec-highに分類されました。
これは、ユーザーが通常通りWebページを閲覧するような行動だけでも悪用される可能性がある脆弱性を意味します。
一方で、さらに上位のsec-criticalは、すでに公開されている、または実際に悪用が確認されている問題に対して使われます。
残りの脆弱性は、80件がsec-moderate、11件がsec-lowに分類されています。
記事では、批判的な意見が続くのは当然だとも指摘されています。
AI業界では、過度な期待感を作り出すことが企業価値を高める手段として使われてきた面があるためです。
そのため、MozillaがClaude Mythos Previewを強く評価することで、「何らかの見返りを得ているのではないか」という疑いが出る可能性もあります。
つまり、今回の公開は議論を終わらせるというより、むしろさらに大きな議論を呼ぶ可能性があります。
それでもGrinstead氏は、今回の詳細な公開はAIを活用した脆弱性検出の有用性を示す明確な証拠だと主張しています。
Mozillaの目的は単純だと同氏は説明しています。
ここ1年ほど、AIが生成した質の低い報告に多くの人が疲れを感じています。
そのため、Mozillaは実際の作業内容の一部を公開し、Bugzillaレポートを閲覧可能にし、より詳しく説明することが重要だと考えました。
それによって、より多くの議論と行動につなげたいという狙いがあります。
Grinstead氏はさらに、「ここにはマーケティング上の意図はない」と述べています。
Mozillaのチームはこのアプローチに強い確信を持っており、特定のモデル提供企業や企業そのものを宣伝したいのではなく、この技術そのものについてメッセージを伝えたいのだと強調しています。
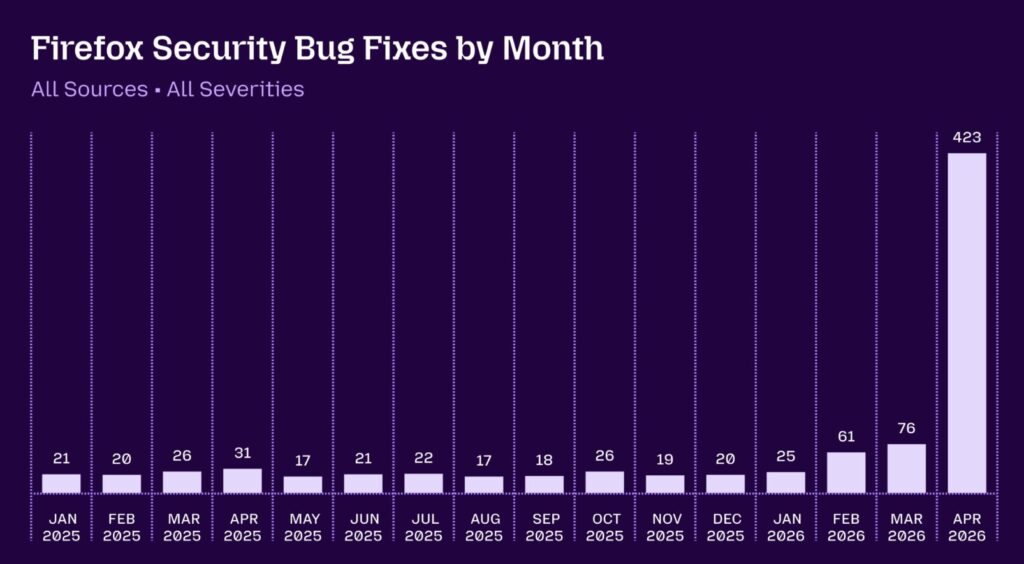
今回のMozillaの公開は、AIによる脆弱性検出が実用段階に近づいていることを示す事例として注目されています。
重要なのは、単にAIモデルにコードを読ませただけではないという点です。
Mozillaは、Firefoxの開発環境に合わせたエージェント・ハーネスを構築し、テストケースの生成、再現、検証、トリアージ、修正までを既存のセキュリティプロセスに組み込みました。
その結果、Claude Mythos Previewを中心とするAIモデルを活用して、Firefox 150で271件の脆弱性修正につなげたと説明されています。
一方で、AIによる脆弱性検出が本当に防御側に有利に働くのか、それとも攻撃側にも同じような力を与えるのかについては、今後も議論が続きそうです。
少なくとも今回の事例は、AIがセキュリティ分野で単なる話題作りではなく、実際の開発現場に入り始めていることを示していると言えます。
私は、クローム利用しています、、、、、、






